一种面向工业云的工作流任务调度方法
本发明属于工业云计算,具体是涉及一种面向工业云的工作流任务调度方法。
背景技术:
1、工作流是由具有一定顺序的待执行任务组成的模型,其用于描述执行流程及各操作步骤。工作流任务调度问题是一个复杂的np难问题,涉及到多个目标的优化,包括执行成本、执行时间和负载均衡等。
2、近年来,随着信息技术快速发展,如云计算、物联网和大数据等技术与工业生产加速融合,这在一定程度上颠覆了传统的生产、生活和商业模式。在工业生产过程中,存在各类形式的计算任务,如设备预测维护、设备控制和产品检测等。
3、随着工业生产中庞大的数据处理需求的不断增长,以及数据复杂性越来越高,许多生产线上的计算设备并不满足计算需求。但云计算满足复杂且庞大的任务需求,可以为工业生产中的工作流任务提供计算、执行、管理和监控等服务,所以通常把工业生产中的计算任务组合为工作流并卸载至云环境下处理。工业云平台能够满足个性化计算需求并为工业制造中的计算任务提供算力服务。工业云下的工作流具有结构复杂、计算规模庞大等特点,但传统的调度算法存在容易陷入局部最优解等不足。
4、如专利申请cn 115794330a公开了一种云计算任务调度方法,使用被囊群搜索机制和粒子群进行求解,计算每只被囊的适应度值,将全部被囊进行排序,并计算每个粒子的适应度值,找出粒子的全局最优量子位置,并应用贪心策略确定新一代被囊群位置。该方法基于粒子群进行改进,但仍存在如早熟收敛、易陷入局部最优、种群多样性等不足,虽然被囊群可以加速粒子搜索效率,但由于解空间中粒子分布特性,导致搜索行为不精准,容易陷入局部最优解而无法跳出。此外,粒子群算法中惯性权重、学习因子参数在算法迭代搜索过程中起到重要作用,参数的设置能够直接影响到最后搜索结果。以上这些不足导致在求解问题复杂度高、任务数量庞大的工业云工作流任务调度问题具有易陷入局部最优、求解时间开销大等局限性。
技术实现思路
1、为解决上述技术问题,本发明提供了一种面向工业云的工作流任务调度方法,建立多目标权衡调度模型,并利用多种群协同的非线性递减权重粒子群算法解决工作流任务调度问题,解决容易陷入局部最优解,求解效率慢等不足之处,提高调度效率。
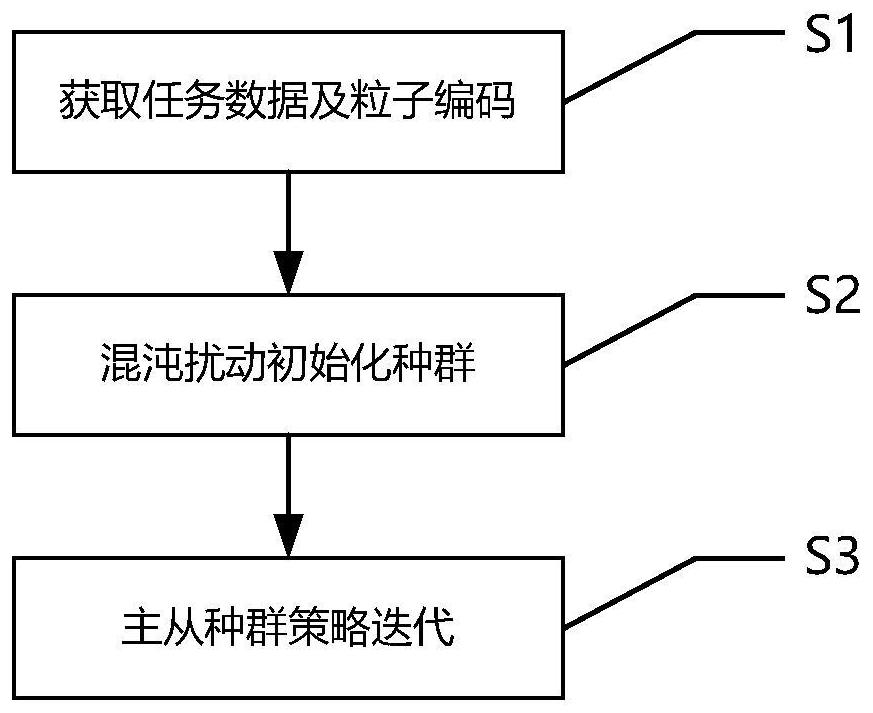
2、本发明所述的一种面向工业云的工作流任务调度方法,包括以下步骤:
3、步骤1、获取工作流任务中待调度任务队列数据,根据任务量级对粒子进行编码,并建立多目标权衡调度模型,作为调度方案优劣的评估标准;
4、步骤2、采用logistic混沌扰动对种群粒子的速度与位置初始化,将所述多目标权衡调度模型作为适应度函数计算粒子的适应度,得出全局最优解和每个粒子的局部最优解;
5、步骤3、采用主从种群策略,根据得出的粒子适应度对种群进行分群并进行迭代更新,使种群能够向不同方向进化,并为主群提供局部最优解信息;其中迭代中采用非线性递减惯性权重策略对粒子的速度与位置进行更新,随着权重值逐渐减小,在局部搜索时逐步压缩搜索空间,实现精细搜索,从而得到最终调度策略。
6、进一步的,步骤1中,解空间内的所有粒子集合形成种群,其中每个粒子皆代表一个解向量,解向量维度代表工作流中的任务数量,粒子每个分量取值代表可调度虚拟机的编号;
7、建立的多目标权衡调度模型为:
8、fitness(x)=a*makespan+b*cost+c*load
9、其中,a、b与c为执行时间、执行成本和负载均衡三个优化目标的权重系数,且a+b+c=1;makespan、cost、load分别为工作流任务总执行时间、总执行成本和负载均衡程度,具体表达式为:
10、
11、
12、
13、其中,为任务ti的执行时间,et和tt分别为任务计算成本与传输成本,为虚拟机vmk中每个核心平均分配的任务数量,avgvm为集群内所有虚拟机核心平均分配的任务数量。
14、进一步的,步骤2具体为:
15、步骤2-1、采用logistic混沌扰动进行种群粒子的速度与位置初始化,通过迭代初始值和参数,在解空间内等概率产生具有混沌性的随机序列,其映射公式如下式:
16、xi+1=μxi(1-xi),i=0,1,2,…,n
17、其中,xi表示第i个混沌变量,对于任意的i,xi∈[0,1],μ为映射可调参数,为使映射进入混沌状态,需满足3.5699456<μ≤4.0;
18、步骤2-2、通过步骤2-1产生相同数量的混沌变量,并将这些混沌变量重新映射到优化空间中,为调度问题产生初始变量,生成均匀分布的初始粒子;
19、步骤2-3、根据步骤1中提出的多目标权衡调度模型作为适应度函数,计算每个粒子的适应度值,记录粒子群中全局最优解和每个粒子的局部最优解。
20、进一步的,步骤3具体为:
21、步骤3-1、对计算后的粒子适应度值进行排序,划分为主群及若干从群,主群和从群分别进行迭代;
22、步骤3-2、所有粒子根据粒子群优化算法进行迭代计算,得到每个粒子的运动速度及位置;具体表达式为:
23、vi(k+1)=ω*vi(k)+c1r1(pbesti-xi(k))+c2r2(gbesti-xi(k)),
24、xi(k+1)=xi(k)+vi(k+1)
25、其中,xi(k)为第i个粒子在第k次迭代的位置,vi(k)为第i个粒子在第k次的速度(粒子移动的距离和方向),ω为惯性权重值,k表示第k代粒子,r1、r2分别表示为局部和全局的运动步长,是[0,1]的随机数;c1、c2为学习系数,分别表示为局部和全局最优对其速度的影响;pbesti、gbesti分别表示为局部最优位置与全局最优位置;
26、步骤3-3、根据迭代后的粒子适应度值进行主从粒子交换:在迭代过程中,当从群中的粒子适应度优于主群最优解时,将该粒子与主群中的最优粒子进行交换,并进行下一步迭代,为主群提供局部最优解信息;
27、步骤3-4、当粒子群迭代结束后,将主群与三个从群中的粒子进行适应度值计算,并将其适应度值最优的粒子作为本次任务调度最优解,得到最终的调度策略。
28、进一步的步骤3-2中,惯性权重迭代策略为:
29、采用一种非线性递减惯性权重,在迭代初期采用最大值惯性权重,进行全局搜索;随着权重值逐渐减小,在局部搜索时逐步压缩搜索空间,实现精细搜索;其描述如下式:
30、
31、其中,ω为惯性权重值,itermax为总迭代次数,iternow为当前迭代次数,l非为线性惯性调节参数,当l>1时,惯性递减速度由快至缓,当0<l<1,惯性递减速度较缓;ω1、ω2为惯性权重的初始值和最终值,初始值分别设为0.9和0.4。
32、本发明所述的有益效果为:本发明所述的方法通过混沌扰动生成均匀分布的初始解,并建立多目标权衡调度模型作为适应度函数计算粒子的适应度来评估调度方案的优劣(即粒子所在位置的权值),得出全局最优解和每个粒子的局部最优解,使用主从多种群策略增加种群多样性,同时采用非线性递减惯性权重策略,可以更好地搜索最佳解,从而实现精细搜索。本发明考虑了工业云中的使用场景,采用多目标权衡调度模型,以任务执行时间、执行成本和负载均衡三目标进行评估,并可根据实际业务需求修改对应目标权值系数,结合其他步骤,在一定程度上加速求解过程,避免陷入局部最优解,可以有效的降低工作流调度的最大完成时间、执行成本,并实现负载均衡的优化。
- 还没有人留言评论。精彩留言会获得点赞!