咨询类工单的分类处理方法、装置、存储介质及电子设备与流程
本技术涉及人工智能领域,具体而言,涉及一种咨询类工单的分类处理方法、装置、存储介质及电子设备。
背景技术:
1、随着金融机构的业务对外拓展和对内监管的调整,客户对于新兴的业务和账户管理有了更多想要咨询的场景,客户通过专线电话、网上留言等渠道咨询金融机构专业问题,金融机构会将客户的咨询问题通过预设的知识库进行回答,并记录下来产生文本数据。其中,知识库的构成是根据客服人员处理历史的咨询类工单识别的类别以及类别对应的专业知识。
2、然而,咨询类工单的文本内容具有类型多样、分布偏斜及标注困难等非结构化特征,且单条工单数据往往包含着多个咨询分类,包括账户管控解锁、办卡进度查询、信用卡协商还款等等,客服人员都可以根据知识库内的资料进行解释回答,如果碰到知识库收录以外的咨询问题,客服人员只能将工单移交给前台工作人员进行处理,但是这样不仅会增加前台工作人员的工作量,而且也会延长业务办理的流程。相关技术中,知识库的补充需要依赖客服人员自行填写,这导致知识库的补充更新缓慢。
3、针对相关技术中对咨询类工单的分类不精确,导致工单处理效率低的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术的主要目的在于提供一种咨询类工单的分类处理方法、装置、存储介质及电子设备,以解决相关技术中对咨询类工单的分类不精确,导致工单处理效率低的问题。
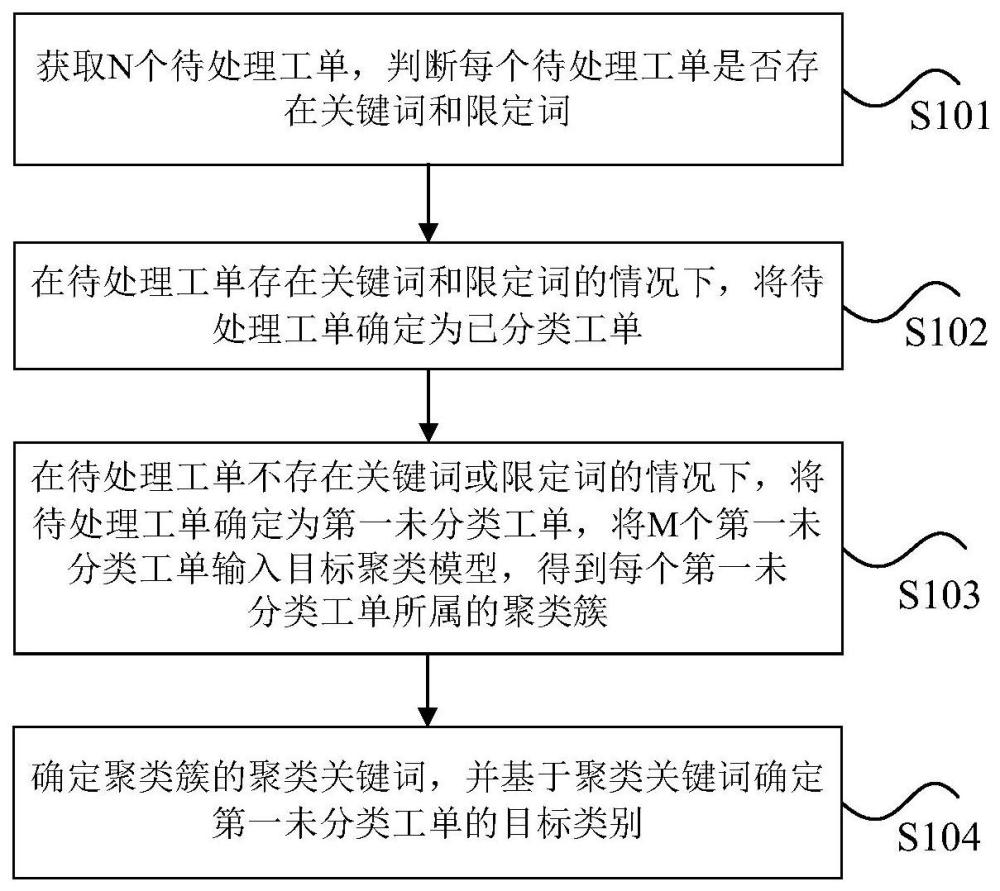
2、为了实现上述目的,根据本技术的一个方面,提供了一种咨询类工单的分类处理方法。该方法包括:获取n个待处理工单,判断每个待处理工单是否存在关键词和限定词,其中,n为正整数,待处理工单为用户对金融机构发起的咨询请求对应的工单,关键词和限定词是预设的关键词词典中的词语,关键词和限定词用于描述待处理工单对应类别的业务场景;在待处理工单存在关键词和限定词的情况下,将待处理工单确定为已分类工单,其中,已分类工单为基于关键词词典已划分类别的工单;在待处理工单不存在关键词或限定词的情况下,将待处理工单确定为第一未分类工单,将m个第一未分类工单输入目标聚类模型,得到每个第一未分类工单所属的聚类簇,其中,m为正整数,m小于n;确定聚类簇的聚类关键词,并基于聚类关键词确定第一未分类工单的目标类别,其中,聚类关键词用于描述聚类簇的聚类主题。
3、可选地,在将待处理工单确定为已分类工单之后,该方法还包括:对于每种类别的已分类工单,计算同一类别的p个已分类工单中任意两个已分类工单之间的相似度,得到一组相似度,其中,p为正整数,p小于n;从一组相似度中确定相似度小于第一相似度阈值的多个目标相似度,获取每个目标相似度对应的一组已分类工单,得到多组已分类工单;确定多组已分类工单中每个已分类工单出现的频次,将频次大于等于频次阈值的已分类工单更新为第二未分类工单,并将第二未分类工单输入目标聚类模型,得到每个第二未分类工单所属的聚类簇;确定聚类簇的聚类关键词,基于聚类关键词确定第二未分类工单的目标类别。
4、可选地,基于聚类关键词确定第一未分类工单的目标类别包括:判断聚类关键词是否为关键词词典中的关键词;在聚类关键词是关键词词典中的关键词的情况下,将关键词对应的类型确定为第一未分类工单的目标类别;在聚类关键词不是关键词词典中的关键词的情况下,基于聚类关键词确定新增类型,将新增类型确定为第一未分类工单的目标类别;在基于聚类关键词确定第一未分类工单的目标类别之后,方法还包括:将新增类型和聚类关键词添加至关键词词典。
5、可选地,将m个第一未分类工单输入目标聚类模型,得到每个第一未分类工单所属的聚类簇包括:从m个第一未分类工单中提取出m个词组,通过预设算法计算每个词组的重要性评估值,得到m个词组的一组向量化特征;确定目标聚类模型预设的聚类主题的数量,将一组向量化特征输入目标聚类模型,得到一组向量化特征的聚类结果,其中,聚类结果包含每个向量化特征命中的聚类主题和命中概率;判断聚类结果中每个向量化特征的命中概率是否大于等于概率阈值;在命中概率大于等于概率阈值的情况下,将向量化特征命中的聚类主题确定为向量化特征对应的第一未分类工单所属的聚类簇。
6、可选地,在判断聚类结果中每个向量化特征的命中概率是否大于等于概率阈值之后,该方法还包括:在命中概率小于概率阈值的情况下,将向量化特征对应的未分类工单确定为未聚类工单,得到一组未聚类工单;将一组未聚类工单的所有向量化特征输入目标聚类模型,得到一组未聚类工单的聚类结果;判断一组未聚类工单的聚类结果中每个向量化特征的命中概率是否大于等于概率阈值;在命中概率大于等于概率阈值的情况下,确定向量化特征对应的未聚类工单为第一未聚类工单,将命中概率对应的聚类主题确定为第一未聚类工单所属的聚类簇;在命中概率小于概率阈值的情况下,确定向量化特征对应的未聚类工单为第二未聚类工单,基于第二未聚类工单重复执行将一组未聚类工单的所有向量化特征输入目标聚类模型的步骤,直到第二未聚类工单的命中概率大于等于概率阈值。
7、可选地,在判断每个待处理工单是否存在关键词和限定词之前,该方法还包括:获取金融机构的历史工单的多个分类类别,从每个分类类别中提取第一预设数量的关键词和第二预设数量的限定词;将每个分类类别以及分类类别中提取的关键词和限定词确定为分类类别对用的条目,得到多个条目;基于多个条目构建关键词词典。
8、可选地,判断每个待处理工单是否存在关键词和限定词包括:从待处理工单中提取多个词组,计算每个词组与关键词词典中的多个关键词的相似度,得到词组与多个关键词的一组关键词相似度;计算每个词组与关键词词典中的多个限定词的相似度,得到词组与多个限定词的一组限定词相似度;在一组关键词相似度中存在至少一个关键词相似度大于等于第二相似度阈值的情况下,确定待处理工单中存在关键词;在一组限定词相似度中存在至少一个限定词相似度大于等于第二相似度阈值的情况下,确定待处理工单中存在限定词。
9、为了实现上述目的,根据本技术的另一方面,提供了一种咨询类工单的分类处理装置。该装置包括:获取单元,用于获取n个待处理工单,判断每个待处理工单是否存在关键词和限定词,其中,n为正整数,待处理工单为用户对金融机构发起的咨询请求对应的工单,关键词和限定词是预设的关键词词典中的词语,关键词和限定词用于描述待处理工单对应类别的业务场景;第一确定单元,用于在待处理工单存在关键词和限定词的情况下,将待处理工单确定为已分类工单,其中,已分类工单为基于关键词词典已划分类别的工单;第二确定单元,用于在待处理工单不存在关键词或限定词的情况下,将待处理工单确定为第一未分类工单,将m个第一未分类工单输入目标聚类模型,得到每个第一未分类工单所属的聚类簇,其中,m为正整数,m小于n;第三确定单元,用于确定聚类簇的聚类关键词,并基于聚类关键词确定第一未分类工单的目标类别,其中,聚类关键词用于描述聚类簇的聚类主题。
10、通过本技术,采用以下步骤:获取n个待处理工单,判断每个待处理工单是否存在关键词和限定词,其中,n为正整数,待处理工单为用户对金融机构发起的咨询请求对应的工单,关键词和限定词是预设的关键词词典中的词语,关键词和限定词用于描述待处理工单对应类别的业务场景;在待处理工单存在关键词和限定词的情况下,将待处理工单确定为已分类工单,其中,已分类工单为基于关键词词典已划分类别的工单;在待处理工单不存在关键词或限定词的情况下,将待处理工单确定为第一未分类工单,将m个第一未分类工单输入目标聚类模型,得到每个第一未分类工单所属的聚类簇,其中,m为正整数,m小于n;确定聚类簇的聚类关键词,并基于聚类关键词确定第一未分类工单的目标类别,其中,聚类关键词用于描述聚类簇的聚类主题,解决了相关技术中对咨询类工单的分类不精确,导致工单处理效率低的问题。通过关键词词典中的关键词和限定词以及目标聚类模型对待处理工单进行分类,进而达到了提高工单处理效率的效果。
- 还没有人留言评论。精彩留言会获得点赞!