运动数据处理方法、关键帧提取模型的训练方法及装置
本技术涉及计算机,特别是涉及一种运动数据处理方法、关键帧提取模型的训练方法及装置。
背景技术:
1、运动数据可以用于创建逼真的角色动画、进行人体运动分析和仿真、实时互动游戏等,在元宇宙、电影制作、游戏开发、体育科学、虚拟现实等领域都有广泛应用。但是在实际应用中,运动数据需要在短时间内大量传输才能实现同步,导致了较高的延迟。
2、相关技术中利用聚类等非监督学习方法,或利用遗传算法等启发式算法对运动数据进行关键帧提取,实现仅传输运动数据中的关键帧,并利用关键帧对整个运动数据进行重建,从而降低传输数据量。然而提取关键帧的过程需要消耗大量的时间,并且提取关键帧的准确率不够理想。
技术实现思路
1、本技术旨在至少解决现有技术中存在的技术问题之一。为此,本技术实施例提供了一种运动数据处理方法、关键帧提取模型的训练方法及装置,能够有效提高关键帧的提取效率和准确率。
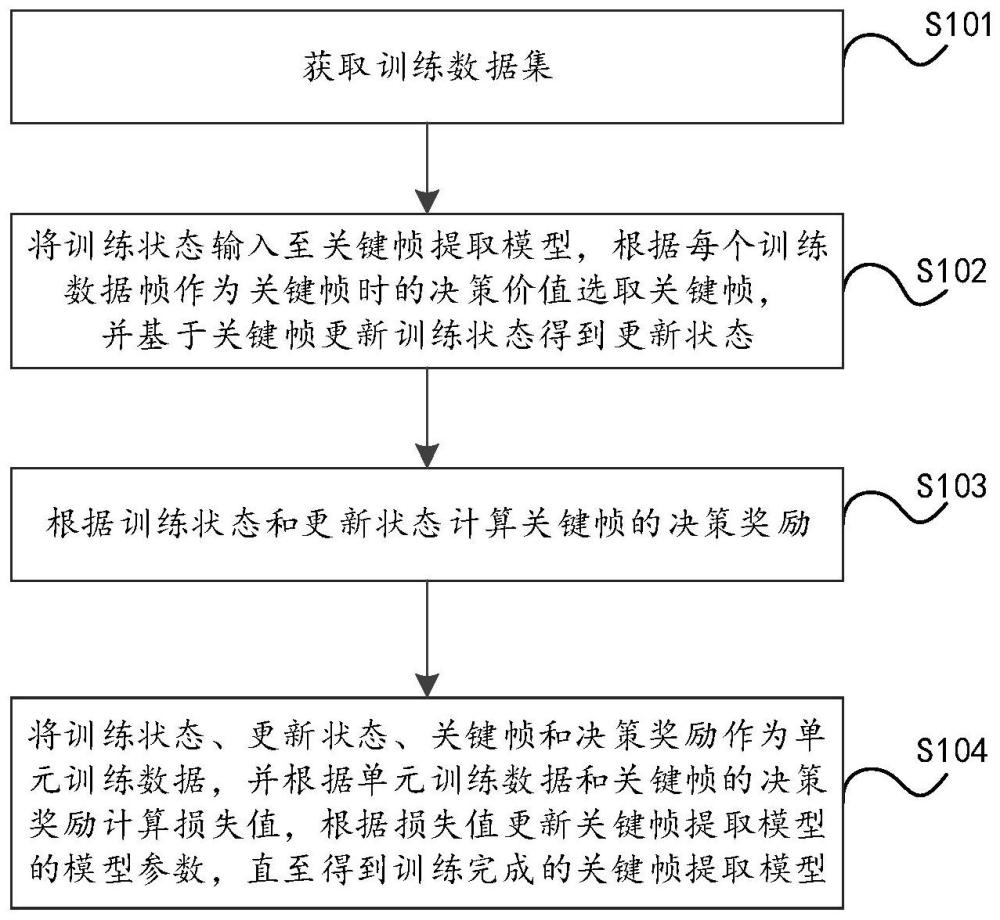
2、第一方面,本技术实施例提供了一种运动数据处理方法,包括:
3、获取包括多个数据帧的运动序列;
4、将所述运动序列输入预先训练的关键帧提取模型进行关键帧提取,得到所述运动序列的目标关键帧;所述关键帧提取模型为深度强化学习模型,用于计算每个所述数据帧对应的回报值,并基于所述回报值选取所述目标关键帧;
5、利用所述目标关键帧对所述运动序列中其他数据帧进行重建,得到所述数据帧对应的重建帧,并基于所述重建帧和所述目标关键帧得到所述运动序列的重建序列。
6、第二方面,本技术实施例还提供了一种关键帧提取模型的训练方法,应用于本技术第一方面实施例所述的运动数据处理方法,包括:
7、获取训练数据集;其中,所述训练数据集包括多个训练状态,所述训练状态包括训练序列和指标序列,所述训练序列包括多个训练数据帧,所述指标序列由所述训练数据帧的关键帧指标构成;
8、将所述训练状态输入至关键帧提取模型,根据每个所述训练数据帧作为关键帧时的决策价值选取关键帧,并基于所述关键帧更新所述训练状态得到更新状态;
9、根据所述训练状态和所述更新状态计算所述关键帧的决策奖励;
10、将所述训练状态、所述更新状态、所述关键帧和所述决策奖励作为单元训练数据,并根据所述单元训练数据和所述关键帧的决策奖励计算损失值,根据所述损失值更新所述关键帧提取模型的模型参数,直至得到训练完成的所述关键帧提取模型。
11、在本技术的一些实施例中,所述根据每个所述训练数据帧作为关键帧时的决策价值选取关键帧,包括:
12、将所述训练序列中每个所述训练数据帧作为关键帧,并计算所述训练数据帧的所述决策价值;
13、将所述决策价值的最高值作为目标决策价值,并选取所述目标决策价值的所述训练数据帧作为所述关键帧。
14、在本技术的一些实施例中,所述根据所述训练状态和所述更新状态计算所述关键帧的决策奖励,包括:
15、基于所述训练状态的所述指标序列计算训练重建误差,以及基于所述更新状态的所述指标序列计算更新重建误差;
16、将所述训练重建误差减去所述更新重建误差,得到参考决策奖励;
17、利用初始状态对应的初始重建误差对所述参考决策奖励进行归一化操作,得到所述关键帧的所述决策奖励;所述初始状态根据所述指标序列的初始值得到。
18、在本技术的一些实施例中,所述训练数据帧中包括多个关键点;计算重建误差的步骤包括:
19、根据所述指标序列得到所述关键帧,在所述关键帧中选取具有时间顺序的前关键帧和后关键帧;其中,所述前关键帧中多个前关键点与所述后关键帧中多个后关键点一一对应,并构成关键点组;
20、利用预设的插值算法对各个所述关键点组进行插值计算,重建所述前关键帧和所述后关键帧之间的非关键帧,得到训练重建帧,所述训练重建帧和所述关键帧构成重建序列;
21、根据所述训练序列和所述重建序列计算重建误差;所述重建误差包括所述训练重建误差、所述更新重建误差或所述初始重建误差。
22、在本技术的一些实施例中,所述根据所述单元训练数据和所述关键帧的决策奖励计算损失值,包括:
23、根据所述决策奖励、奖励折扣参数和长期奖励计算所述单元训练数据的期望价值;
24、将所述单元训练数据输入至所述关键帧提取模型,得到对应的参考价值;
25、根据所述参考价值和所述期望价值计算所述关键帧提取模型的损失值。
26、在本技术的一些实施例中,所述单元训练数据存储在回放缓存中,所述回放缓存包括缓存容量;所述方法还包括:
27、在所述训练数据集中随机选取所述训练状态,并将所述训练状态输入至所述关键帧提取模型,得到对应的单元训练数据并存储至所述回放缓存中,直至达到所述缓存容量;
28、根据所述单元训练数据和所述关键帧的决策奖励计算损失值,根据所述损失值更新所述关键帧提取模型的模型参数,若所述关键帧提取模型未满足预设的收敛条件,则重复上述过程更新所述回放缓存中的所述单元训练数据,并训练所述关键帧提取模型。
29、在本技术的一些实施例中,所述获取训练数据集之前,还包括:
30、从预设的运动数据库中获取动作序列,并调整所述动作序列的帧率;
31、根据预设的时间间隔对所述动作序列进行分割,得到多个训练序列;其中,各个所述训练序列包括相同数量的训练数据帧;
32、对所述训练数据帧的关键帧指标进行初始化,得到所述指标序列的初始值;其中,所述关键帧指标为第一指标值时指示所述训练数据帧为关键帧,所述关键帧指标为第二指标值时指示所述训练数据帧为非关键帧。
33、第三方面,本技术实施例还提供了一种关键帧提取模型的训练装置,应用如本技术第二方面实施例所述的关键帧提取模型的训练方法,包括:
34、获取模块,用于获取训练数据集;其中,所述训练数据集包括多个训练状态,所述训练状态包括训练序列和指标序列,所述训练序列包括多个训练数据帧,所述指标序列由所述训练数据帧的关键帧指标构成;
35、提取模块,用于将所述训练状态输入至关键帧提取模型,根据每个所述训练数据帧作为关键帧时的决策价值选取关键帧,并基于所述关键帧更新所述训练状态得到更新状态;
36、奖励模块,用于根据所述训练状态和所述更新状态计算所述关键帧的决策奖励;
37、训练模块,用于将所述训练状态、所述更新状态、所述关键帧和所述决策奖励作为单元训练数据,并根据所述单元训练数据和所述关键帧的决策奖励计算损失值,根据所述损失值更新所述关键帧提取模型的模型参数,直至得到训练完成的所述关键帧提取模型。
38、第四方面,本技术实施例还提供了一种电子设备,包括存储器、处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如本技术第二方面实施例所述的关键帧提取模型的训练方法。
39、第五方面,本技术实施例还提供了一种计算机可读存储介质,所述存储介质存储有程序,所述程序被处理器执行实现如本技术第二方面实施例所述的关键帧提取模型的训练方法。
40、本技术实施例至少包括以下有益效果:
41、本技术实施例提供了一种运动数据处理方法、关键帧提取模型的训练方法及装置。运动数据处理方法中首先获取包括多个数据帧的运动序列,然后将运动序列输入预先训练的关键帧提取模型进行关键帧提取,得到运动序列的目标关键帧。其中,关键帧提取模型为深度强化学习模型,用于计算每个数据帧对应的回报值,并给予回报值选取目标关键帧。最后利用目标关键帧对运动序列中其他数据帧进行重建,得到数据帧对应的重建帧,并给予重建帧和目标关键帧得到运动序列的重建序列。由此通过深度强化学习模型对运动序列进行关键帧提取,基于数据帧的回报值选取目标关键帧,即可根据目标关键帧对运动序列进行重建,从而有效了提高关键帧的提取效率和准确率。
42、本技术的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!