一种基于大模型的数据协同处理方法及系统与流程
本发明涉及数据处理,具体涉及一种基于大模型的数据协同处理方法及系统。
背景技术:
1、随着人工智能技术的不断发展,大模型在各个领域的应用越来越广泛。然而,大模型的训练过程通常需要大量的计算资源和时间,使得数据协同处理成为了一个重要的问题。
2、申请号为cn202010512196.8的专利公开了一种云端混合加速器的调度方法、计算机设备及存储介质,涉及人工智能技术。该方法包括:接收客户端发送的模型并行值;根据模型并行值和异构的加速器资源确定环境变量;根据环境变量确定加速器拓扑信息;根据拓扑信息和环境变量调度加速器执行模型训练任务。能够根据客户端发送的模型并行值,计算异构加速器场景中加速器使用的环境变量,根据环境变量确定异构场景的加速器拓扑信息,根据该拓扑信息和环境变量调度异构的ai加速器执行ai模型训练,进而实现多个代际的ai加速器联合执行ai模型训练任务。
3、但仍然存在以下不足之处:无法对训练用数据集进行处理并分析,也无法对处理数据的计算节点进行分析并智能选用,导致训练速度低,易于出现数据处理误差,导致难以保证训练结果的准确性和可靠性,因此,开发一种基于大模型的数据协同处理方法及系统,能够提高数据协同处理速度并保证训练结果的准确性和可靠性,具有重要的现实意义。
技术实现思路
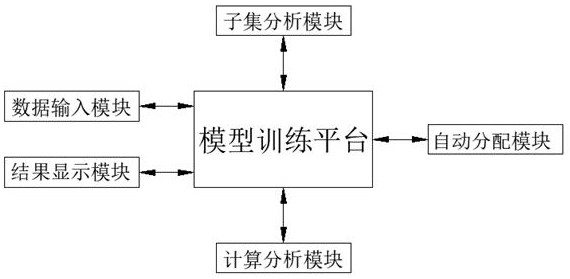
1、本发明的目的在于提供一种基于大模型的数据协同处理方法及系统,用户利用数据输入模块将大模型训练用的数据集进行上传,通过模型训练平台将数据集分割若干个数据子集,同时生成子集分析指令,通过子集分析模块接收到子集分析指令后获取数据子集的优先处理参数,通过模型训练平台根据优先处理参数获得优先处理系数,并根据优先处理系数获得数据子集分配名单,同时生成计算分析指令,通过计算分析模块接收到计算分析指令后获取分析节点的优先计算参数,通过模型训练平台根据优先计算参数获得优先计算系数,并根据优先计算系数获得计算节点分配名单,通过自动分配模块根据数据子集分配名单和计算节点分配名单将数据子集和分析节点进行对应,并利用分析节点对数据子集进行计算,待每个分析节点计算完成,通过结果显示模块将所有的计算结果进行汇合并显示,完成大模型训练,解决了现有的用于数据处理加速器的模糊大模型训练方法无法对训练用数据集进行处理并分析,也无法对处理数据的计算节点进行分析并智能选用,导致训练速度低,易于出现数据处理误差,导致难以保证训练结果的准确性和可靠性的问题。
2、本发明的目的可以通过以下技术方案实现:
3、一种基于大模型的数据协同处理方法,包括以下步骤:
4、步骤s1:用户利用数据输入模块将大模型训练用的数据集进行上传,并将数据集发送至模型训练平台;
5、步骤s2:模型训练平台将数据集分割若干个数据子集,同时生成子集分析指令,并将子集分析指令发送至子集分析模块;
6、步骤s3:子集分析模块接收到子集分析指令后获取数据子集的优先处理参数,优先处理参数包括数容值sr、均时值jt,并将优先处理参数发送至模型训练平台;
7、步骤s4:模型训练平台根据优先处理参数获得优先处理系数yc,并根据优先处理系数yc获得数据子集分配名单,并将数据子集分配名单发送至自动分配模块,同时生成计算分析指令,并将计算分析指令发送至计算分析模块;
8、步骤s5:计算分析模块接收到计算分析指令后获取分析节点i的优先计算参数,优先计算参数包括计算值jh、网速值ws以及存储值cc,并将优先计算参数发送至模型训练平台;
9、步骤s6:模型训练平台根据优先计算参数获得优先计算系数yji,并根据优先计算系数yji获得计算节点分配名单,并将计算节点分配名单发送至自动分配模块;
10、步骤s7:自动分配模块根据数据子集分配名单和计算节点分配名单将数据子集和分析节点i进行对应,并利用分析节点i对数据子集进行计算,待每个分析节点i计算完成,将计算结果发送至结果显示模块;
11、步骤s8:结果显示模块将所有的计算结果进行汇合并显示,完成大模型训练。
12、作为本发明进一步的方案:所述模型训练平台将数据集分割的具体过程如下:
13、获取数据集中的所有数据的储存时刻,获取最早的储存时刻和最晚的储存时刻,并获得两者之间的时间段,并将其标记为储存时间段;
14、将储存时间段按照预设的分割时长进行分割,形成若干个分割时间段,将所有数据的储存时刻与分割时间段进行比对,若储存时刻∈分割时间段,则同一分割时间段中储存时刻对应的数据进行汇合,形成数据子集,同时生成子集分析指令,并将子集分析指令发送至子集分析模块。
15、作为本发明进一步的方案:所述子集分析模块获取优先处理参数的具体过程如下:
16、接收到子集分析指令后获取数据子集中的数据数量和数据所占容量,并将其分别标记为据数值js和据容值jr进行量化处理,提取据数值js和据容值jr的数值,并将其代入公式中计算,依据公式 得到数容值sr,其中,δ为预设的参数调节因子,取δ=2.35,j1、j2分别为设定的据数值js和据容值jr对应的预设比例系数,j1、j2满足j1+j2=1.24,0<j2<j1<1,取j1=0.68,j2=0.56;
17、获取数据子集中的所有的数据的储存时刻与当前时刻,获得两者之间的时间差值,并将其标记为时长值sc,获取所有的时长值sc的平均值,并将其标记为均时值jt;
18、将数容值sr、均时值jt发送至模型训练平台。
19、作为本发明进一步的方案:所述模型训练平台获得数据子集分配名单的具体过程如下:
20、将数容值sr、均时值jt进行量化处理,提取数容值sr、均时值jt的数值,并将其代入公式中计算,依据公式 得到优先处理系数yc,其中,c1、c2分别为设定的数容值sr、均时值jt对应的预设权重因子,c1、c2满足c1>c2>1.573,取c1=2.11,c2=1.79;
21、将所有的数据子集按照优先处理系数yc从大到小的顺序进行排序,形成数据子集分配名单,并将数据子集分配名单发送至自动分配模块,同时生成计算分析指令,并将计算分析指令发送至计算分析模块。
22、作为本发明进一步的方案:所述计算分析模块获取优先计算参数的具体过程如下:
23、接收到计算分析指令后获取所有的计算节点,并将其依次标记为分析节点i,i=1、……、n,n为正整数;
24、获取分析节点i历史数据中单位时间内计算的数据数量和数据总字节数,并将其分别标记为算数值ss和算节值sj,将算数值ss和算节值sj进行量化处理,提取算数值ss和算节值sj的数值,并将其代入公式中计算,依据公式得到计算值jh,其中,s1、s2分别为设定的算数值ss和算节值sj对应的预设比例系数,s1、s2满足s1+s2=1,0<s1<s2<1,取s1=0.28,s2=0.72;
25、获取分析节点i的单位时间的平均网络速度,并将其标记为均速值jk,获取分析节点i的单位时间的最大网络速度和最小网络速度,获取两者之间的速度差值,并将其标记为差速值cs,将均速值jk、差速值cs进行量化处理,提取均速值jk、差速值cs的数值,并将其代入公式中计算,依据公式得到网速值ws,其中,w1、w2分别为设定的均速值jk、差速值cs对应的预设比例系数,w1、w2满足w1+w2=1,0<w2<w1<1,取w1=0.69,w2=0.31;
26、获取分析节点i的最大存储容量和剩余存储容量,并将其分别标记为储容值cr和余容值yr,将储容值cr和余容值yr进行量化处理,提取储容值cr和余容值yr的数值,并将其代入公式中计算,依据公式得到存储值cc,其中,r1、r2分别为设定的储容值cr和余容值yr对应的预设比例系数,r1、r2满足r1+r2=1,0<r1<r2<1,取r1=0.35,r2=0.65;
27、将计算值jh、网速值ws以及存储值cc发送至模型训练平台。
28、作为本发明进一步的方案:所述模型训练平台获得计算节点分配名单的具体过程如下:
29、获取计算值jh、网速值ws以及存储值cc三者的乘积,并将其标记为优先计算系数yji;
30、将所有的分析节点i按照优先计算系数yji从大到小的顺序进行排序,形成计算节点分配名单,并将计算节点分配名单发送至自动分配模块。
31、作为本发明进一步的方案:所述自动分配模块将数据子集和分析节点i进行对应的具体过程如下:
32、获取数据子集分配名单中各个数据子集和计算节点分配名单中各个分析节点i的序号,并将相同序号的数据子集和分析节点i进行一一对应,并利用分析节点i对数据子集进行计算,待每个分析节点i计算完成,将计算结果发送至结果显示模块。
33、本发明的有益效果:
34、(1)本发明用户利用数据输入模块将大模型训练用的数据集进行上传,通过模型训练平台将数据集分割若干个数据子集,同时生成子集分析指令,通过子集分析模块接收到子集分析指令后获取数据子集的优先处理参数,通过模型训练平台根据优先处理参数获得优先处理系数,并根据优先处理系数获得数据子集分配名单,同时生成计算分析指令,通过计算分析模块接收到计算分析指令后获取分析节点的优先计算参数,通过模型训练平台根据优先计算参数获得优先计算系数,并根据优先计算系数获得计算节点分配名单,通过自动分配模块根据数据子集分配名单和计算节点分配名单将数据子集和分析节点进行对应,并利用分析节点对数据子集进行计算,待每个分析节点计算完成,通过结果显示模块将所有的计算结果进行汇合并显示,完成大模型训练;
35、(2)本发明大模型用数据协同处理方法首先将大模型训练用的数据集进行分割成数据子集,并对数据子集进行数据采集与分析,获取优先处理参数,根据优先处理参数获得的优先处理系数能够综合衡量数据子集的优先处理程度,也间接反映其处理难度,且优先处理系数越大表示优先处理程度越高,之后对处理数据的计算节点进行数据采集与分析,获取优先计算参数,根据优先计算参数获得的优先计算系数能够综合衡量计算节点的优先计算程度,也间接反映其数据处理能力,最终通过排序的序号将数据子集和计算节点进行对应,并令所有的计算节点同时对数据子集进行数据处理,最终将处理结果汇合并显示;
36、(3)本发明大模型数据协同处理采用分布式计算和数据并行处理技术,能够充分利用计算资源的优势,提高训练效率,而且选用性能好的计算节点进行数据处理,能够提高大模型的训练速度,减少数据处理误差,进而能够保证训练结果的准确性和可靠性,
- 还没有人留言评论。精彩留言会获得点赞!