一种基于微调的虚拟人的角色扮演优化方法与流程
本发明属于计算机,具体涉及一种基于微调的虚拟人的角色扮演优化方法。
背景技术:
1、uncensored large language model(uncensored llm)是一种机器学习模型,旨在理解和生成类似人类的文本,使其能够以更高级的方式模拟人类,而不仅仅是复制简单的人类行为。uncensored llm在广泛的数据集上进行训练,并且可以执行多种任务。
2、近年来由uncensored llm驱动的角色扮演代理领域得到了迅速的扩展和增长,并且市场需求已得到ai情感陪伴行业的市场验证且规模较大,全网网页端应用数量80+,移动端应用40+,网页端全网访问量在1.3亿+,独立访客数在约4000w。uncensored llm在角色扮演代理领域的应用已经扩展到不同的环境中,例如虚构角色的ai表示,以及电子游戏中的ai非玩家角色(non-player character,npc)。如下表所示,character.ai、janitorai.com和candy.ai在adult、games上的应用相对较多。
3、
4、目前的llm是在大量的互联网数据语料库上进行预训练的,他们丰富的参数知识有助于他们执行各种各样的任务。然而,llm同时受参数化世界知识的影响,导致角色扮演角色的行为与角色不符,并对其知识范围之外的事物产生幻觉。解决幻觉现象是推动uncensored llm的一个关键因素。基于llm设计角色扮演代理,引入合适的数据集,并在训练过程中通过使用预校准的置信度阈值来调节参数知识,能够减少角色幻觉现象,提供一种新的角色扮演体验。
5、构建能够模拟具有个性化特征的人类行为的自主代理是一个长期存在的挑战。角色扮演对话系统应该产生与所分配的角色和故事情节相关的事实相一致的反应,而目前的角色扮演方法均表现出难以应对开放域领域的事物,在角色扮演中导致角色产生幻觉和表现不佳。另外,目前的角色扮演对话系统并未专注于高效的微调或部署应用,具体来说具有以下的缺点:
6、1、缺乏合适的数据集:目前还没有数据集可以解决对时间敏感的角色扮演或不太受欢迎的角色的幻觉问题。而由于llm缺乏足够的参数化知识,导致不太受欢迎的角色产生幻觉和表现不佳;
7、2、缺乏减少参数知识引起的幻觉的有效机制:目前的角色扮演方法主要依赖于角色画像提示和时间敏感的知识检索,严重依赖于llm的参数化知识,即角色扮演的角色可能会对故事线之外的事情,或者提前展示对事件的了解产生幻觉;
8、3、目前的角色扮演对话系统缺乏高效的部署方案:当前的角色扮演对话系统依赖llm,其训练和推理任务往往分开进行,导致资源利用率不高。由于角色扮演对话系统的训练和部署推理都需要大量的计算资源和内存,传统的分离式流程在设备资源紧张时难以高效运行。然而,目前缺乏成熟的方案来实现训练和部署推理的整合,如何在不影响推理性能的前提下,灵活地将闲置资源用于模型训练,是一个亟待解决的问题。
技术实现思路
1、针对以上严重依赖llm参数化知识及数据集缺失问题,本发明提出了一种基于微调的虚拟人的角色扮演优化方法,专注于减轻虚拟角色角色扮演的幻觉,能够将对抗性会话的事实准确性提高到18.4%,将时间敏感会话的时间幻觉减少44.5%,将不太受欢迎的角色的事实准确性提高23%。另外,本发明还不容易受到由于检索质量差而导致的性能下降的影响。为解决以上技术问题,本发明所采用的技术方案如下:
2、一种基于微调的虚拟人的角色扮演优化方法,包括如下步骤:
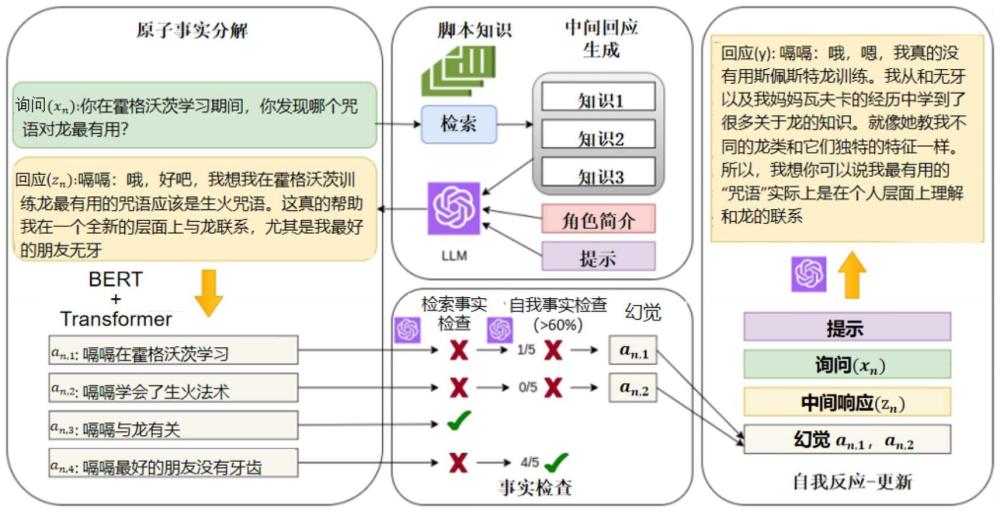
3、s1,收集脚本,利用gpt语言模型获取角色概要文档集,基于脚本生成会话查询集和情节描述文本集;
4、s2,基于步骤s1得到的会话查询集、情节描述文本集和角色概要文档集利用倒排索引方法检索每个会话查询对应的角色概要文档和相关文本知识集,基于检索出的角色概要文档和相关文本知识集利用llm模型生成每个会话查询所对应的中间响应;
5、s3,基于步骤s2得到的中间响应和步骤s1得到的角色概要文档利用预训练的bert模型和transformer模型对中间响应进行分割生成原子事实序列;
6、s4,根据步骤s2得到的相关文本知识集利用llm模型对步骤s3得到的原子事实序列中的每个原子事实进行验证,基于验证结果输出不支持原子事实序列;
7、s5,将步骤s1得到的会话查询集、步骤s2得到的中间响应、步骤s4得到的每个会话查询的不支持原子事实序列输入llm模型生成对应于每个会话查询的最优会话响应。
8、所述步骤s2包括如下步骤:
9、s2.1,基于会话查询集和情节描述文本集利用倒排索引方法检索每个会话查询相对应的相关文本知识集;
10、s2.2,基于会话查询集和角色概要文档集利用倒排索引方法检索每个会话查询相对应的一个角色概要文档;
11、s2.3,将会话查询集、步骤s2.1得到的相关文本知识集和步骤s2.2得到的角色概要文档输入llm模型生成每一个会话查询所对应的中间响应。
12、所述步骤s3包括如下步骤:
13、s3.1,将步骤s1得到的角色概要文档集输入预训练的bert模型获取每个角色的角色知识嵌入;
14、s3.2,将步骤s2得到的中间响应输入预训练的bert模型生成查询向量,将查询向量与步骤s3.1得到的角色知识嵌入进行拼接得到扩展向量;
15、s3.3,基于步骤s3.2得到的扩展向量对transformer模型的注意力权重进行更新,利用更新后的transformer模型对中间响应进行分割生成原子事实序列。
16、所述注意力权重更新的公式为:
17、
18、式中,k表示所有角色知识嵌入所构成的嵌入矩阵,表示扩展向量,d表示角色知识嵌入的维度。
19、在步骤s3.3中,对中间响应进行分割生成原子事实序列时的分割点的表达式为:
20、m=topk(argsort(c));
21、式中,c表示中间响应的分割点概率集合,m表示中间响应的分割点集合,通过选取分割点概率集合中概率较高的k个分割点得到;
22、分割点概率集合中每一个分割点概率的计算公式为:
23、
24、式中,表示注意力权重的第i个行第j列的元素,j表示中间响应经过分词处理后的词个数,σ(·)表示sigmoid函数,c(i)表示中间响应的第i个词作为分割点的概率。
25、所述步骤s4包括如下步骤:
26、s4.1,构建空的支持原子事实序列和不支持原子事实序列,初始化核验轮数m=1,设置置信阈值t和查询次数ε;
27、s4.2,将步骤s3得到的原子事实序列的第m个原子事实、步骤s2得到的对应的相关文本知识集输入llm模型判断原子事实是否被对应的相关文本知识集支持,如是,将第m个原子事实加入对应的支持原子事实序列,执行步骤s4.3,否则,执行步骤s4.4;
28、s4.3,执行m=m+1,判断m≤|m|,若是,返回执行步骤s4.2,否则,返回步骤s4.1对下一个会话查询所对应的原子事实序列的每个原子事实进行验证,|m|表示会话查询中原子事实序列m中的原子事实的个数;
29、s4.4,将第m个原子事实输入llm模型δ次得到δ个验证结果,计算模型支持率若是,将第m个原子事实加入对应的支持原子事实序列,否则,将第m个原子事实加入对应的不支持原子事实序列,β表示验证结果中支持原子事实的次数。
30、本发明的有益效果:
31、1、基于情节描述文档构建充分的对抗性提示查询和开放域对话查询任务,模拟角色对话系统在时间敏感和不太受欢迎角色方面产生的幻觉,导致角色响应不连贯,降低用户体验的问题。构建的查询任务有助于角色对话系统进行最终响应的微调,实现缓解角色幻觉的目的;
32、2、提出了角色扮演方法roleact,可以调节由互联网大量语料数据训练的原始llm对角色反应的影响来减轻角色幻觉。首先基于非参数知识库生成中间响应;然后基于角色知识嵌入使用bert和transformer模型进行原子事实划分,通过捕获角色的特征和行为划分贴近角色的原子事实;使用非参数化知识库和原始互联网语料训练的原始llm对原子事实验证;最后保留由参数化验证所支持的所有事实,以及置信度高于校准阈值的事实,以更新llm的响应。通过使用预校准的置信度阈值来调节原始互联网语料对于llm的影响,以在事实性和信息性之间找到平衡,排除不利于角色对话连贯性的内容,获得缓解幻觉的最优化响应;
33、3、设计微调训练和部署推理一体化的部署方案,即在同一硬件环境中动态切换训练与推理任务,目标是在不增加硬件负担的情况下,最大化资源利用率,优化系统的响应速度,并在硬件能力允许的情况下,支持连续的模型改进。提出角色扮演对话系统微调部署,设计角色扮演对话系统在使用高峰期主要用于推理服务,而在非高峰期将资源重新分配用于模型的微调训练。
- 还没有人留言评论。精彩留言会获得点赞!