一种模拟游戏三维模型建立方法与流程
本发明涉及一种三维模型建立方法,属于网络游戏。
背景技术:
1、计算机游戏是以计算机为操作平台,通过人机互动形式实现的,能够体现当前计算机技术较高水平的一种新形式的娱乐方式。随着互联网的普及,计算机网络游戏开始盛行起来,计算机网络游戏又称互联网游戏,它以互联网为传输媒介,以游戏运营商服务器和用户计算机为处理终端,以游戏客户端软件为信息交互窗口,旨在实现娱乐、休闲、交流和取得虚拟成就,且具有可持续性和个体多人在线体验。近年来,互联网游戏种类和互联网游戏运营商不断增多,传统的二维场景游戏已经难以满足广大游戏爱好者的需求,三维场景模拟游戏不断出现,已经几乎取代了传统的二维场景游戏;但基于三维建模的游戏在进行场景转换过程中,其中人物图像及环境图像经常会出现亮度不够的情况,尤其是带有雨水的三维模型场景,严重影响用户游戏体验感。
技术实现思路
1、本发明为解决基于三维建模的游戏在进行场景转换过程中,其中人物图像及环境图像经常会出现亮度不够的情况,尤其是带有雨水的三维模型场景,严重影响用户游戏体验感的问题,进而提出一种模拟游戏三维模型建立方法。
2、本发明为解决上述问题采取的技术方案是:本发明的步骤包括:
3、步骤1、对带有三维模型的游戏场景转换图像进行增亮;
4、步骤2、对带有雨水的三维模型游戏场景中进行去雨处理;
5、步骤3、输出增亮和去雨处理的三维模型游戏场景。
6、进一步的,步骤1具体包括:
7、步骤101、获取数据集图像;
8、步骤102、数据集图像增强;
9、步骤103、基于lime方法的亮度增强模型训练;
10、步骤104、模型评估与优化。
11、进一步的,步骤101具体包括:使用自动化网络爬虫技术收集细节不易识别的场景图像;所有图像在收集后存储于数据处理中心,以便进行后续的图像预处理。
12、进一步的,对于收集到的细节缺失的场景图像数据,执行以下预处理操作以增强数据集的多样性并适应模型输入需求:
13、步骤1021、旋转和镜像:图像数据首先经过随机旋转和镜像处理;此操作的目的是通过模拟不同的观测角度来增加数据集的多样性,从而提高模型在实际应用中的鲁棒性和泛化能力;
14、步骤1022、随机裁剪:从原始珊瑚图像中随机裁剪出256x256像素的图像区块,此步骤确保所有图像块具有统一的尺寸,适合作为深度学习模型的输入,这一操作也有助于模型学习从局部特征中识别和处理图像,增强模型对于珊瑚图像各部分的处理能力。
15、进一步的,步骤103具体包括:亮度增强模型的训练是通过结合lime方法与深度学习技术来实现的,以确保最终模型能有效增强场景图像的亮度和清晰度,具体步骤如下:
16、步骤1031、模型架构设计;
17、设计一个基于卷积神经网络的深度学习模型架构,该模型结构包括多个卷积层、激活层及池化层,每一层的设计都旨在提取和处理图像的特定特征,模型的输入层接受经过预处理的场景图像,输出层则生成亮度增强后的场景图像;
18、步骤1032、数据准备与预处理;
19、在模型训练之前,对收集到的模糊不清的场景图像进行必要的预处理,使用高斯模糊和双边滤波等方法去除图像噪点,同时保留重要的边缘信息;
20、步骤1033、光照图估计网络训练;
21、采用基于retinex理论的深度学习方法,该训练过程旨在使模型精确地学习和预测低光照条件下的光照分布,从而实现场景图像亮度的有效增强;
22、建立的retinex理论具体公式如下:
23、i(x,y)=r(x,y)·l(x,y)
24、其中,i(x,y)表示输入的场景图像在位置(x,y)的像素值;r(x,y)表示场景内三维模型反射率图在位置(x,y)的像素值;l(x,y)表示场景内三维模型图在位置(x,y)的像素值;
25、为了训练模型准确估计光照和反射率,使用了联合损失函数来最小化预测值与真实值之间的误差,这一损失函数包括光照估计和反射率估计损失两个组成部分,通过最小化预测值与真实值之间的误差,提高了模型在不同光照条件下的适应能力和精确度;
26、联合损失函数定义为:
27、
28、其中,α,β是权重参数,用于平衡光照损失和反射率损失的重要性;是光照估计的损失函数;是反射率估计的损失函数;
29、在训练过程中,模型利用估计出的光照分布对低光照珊瑚图像进行亮度增强。通过学习正常光照条件下的珊瑚图像特征,模型在低光照条件下准确地重建光照图,提高原本细节缺失的珊瑚图像的亮度和对比度;
30、步骤1034、亮度调整与优化;
31、在光照图估计后,应用直方图均衡化和gamma算法对先前估计出的光照图进行增强,来调整图像的亮度和对比度;
32、步骤1035、图像融合与输出;
33、将增强后的场景图像与原始颜色失真细节缺失的场景图像进行融合处理,采用拉普拉斯金字塔融合和基于波段融合的图像融合技术,确保两者在像素级别上实现无缝结合;这一步通过多尺度的分解和重构,精确地保持了原始珊瑚图像的细节同时引入增强后图像的亮度优势;融合后的图像在视觉效果上显著优于原图,不仅更加明亮清晰,而且保持了自然的色彩表现。
34、进一步的,步骤104具体包括:
35、使用基于改进的结构相似性指数方法来评估由亮度增强网络模型处理后的场景图像,在ssim公式基础上加入了亮度调整因子b和对比度调整因子c,改进后的ssim计算公式为:
36、
37、其中,μx、μy分别表示场景图像x和y的亮度均值,反映了场景中三维模型的平均光强;σx、σy分别表示场景图像×和y的方差,代表了场景中中光照变化的程度;σxy表示场景图像×和y的协方差,描述了两个图像在亮度变化上的共同趋势;c1、c2是小常数,用于保证计算的稳定性,避免分母为零的情况;b=|μy-μx|表示亮度调整因子,反映了增强过程中平均光强的变化c=|μy-μx|表示对比度调整因子,量化了增强过程中图像对比度的变化;
38、对于数据库中每对原始低照度下失真模糊的场景图像和视觉效果完美的场景图像,用处理后的细节增强图像与完美图像来计算ssim值,来定量地评估模型的增强效果;ssim值的范围从-1到1,其中1表示完全相似;高ssim值表明模型在保持图像自然色彩和细节的同时,有效增强了图像的亮度和对比度;最后,根据ssim评估结果,进行参数调整和算法迭代;包括调整网络参数,如学习率、层数和滤波器大小等,以优化模型性能此外,对算法进行迭代优化,包括调整亮度和对比度调整因子的计算方法,以精细控制场景图像质量改善。
39、进一步的,步骤2具体包括:
40、步骤201、带雨图像生成和筛选;
41、步骤202、rgb图像去雨模型;
42、步骤203、引入全局语义引导作为额外的监督。
43、进一步的,步骤201具体包括:
44、步骤2011、通过一个变分推断框架进行雨纹生成;
45、基于变分推断框架的雨纹合成网络结构的原理为:(1)
46、o=r+b. (1),
47、其中,o是单幅有雨图,r是雨纹图,b是干净的无雨背景图;
48、将雨纹层r建模成如下的生成器形式:
49、r=gθ(z).(2),
50、其中,z是隐变量,θ表示生成器的参数;
51、为了保证降雨因子各向同性,该网络假设隐变量z的先验分布服从均值为0,协方差为单位矩阵的正态分布,即;
52、z~n(z|0,i).(3),
53、通过调整z的特定维度来生成不同的雨水形态;
54、背景建模;
55、将x嵌入到b的高斯先验分布中;
56、
57、其中,是衡量x和b之间的相似度的超参数;
58、根据上式得到雨图o的概率分布为:
59、o~pθ(o|z,b). (5),
60、其中,pθ(·)表示该分布同时也依赖于生成器的参数θ;
61、将生成雨水图像的任务转向学习一般分布p(o)的任务,p(o)表示成如下形式:
62、p(o)=∫∫pθ(o|z,b)p(z)p(b)dzdb. (6),
63、其中p(z)和p(b)分别表示z和b的先验分布;
64、基于变分推断框架的隐分布学习;
65、采用diffnet模型来单目深度估计rgb图像irgb(x)的深度图d(x),获得d(x)后,用一个超参数β来调节所需的散射强度,根据如下公式获得传输率t(x).
66、t(x)=e-β×d(x). (7),
67、利用超参数a来调节有雾图像的颜色和强度,通过以下公式得到有雾图像ihaze(x);
68、ihaze(x)=irgb(x)×t(x)+a×(1-t(x)). (8),
69、采用屏幕混合模型(smb)进行雨纹和背景图的合成工作,公式如下:
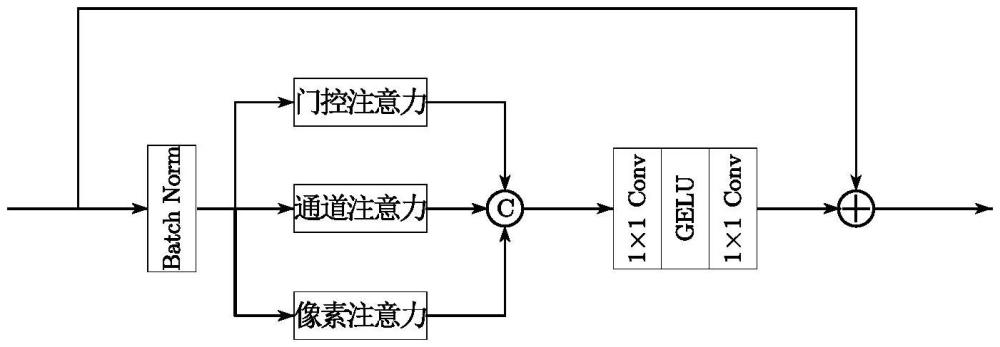
70、r=b+s-b⊙s. (9),
71、其中,r表示合成的雨图,b表示无雨背景图,s表示雨纹图;
72、将数据集裁剪成256×256大小的图片并采用vrgnet模型合成具有不同方向、规模、厚度的雨水图像,最后用上述的asm模型进行雨雾的合成,构建出三元组用于后续工作。
73、进一步的,步骤202具体包括:
74、并行注意力模块;包含一个门控注意力、一个通道注意力和像素注意力;在进行基于平行注意力特征提取之前对输入特征用批标准化进行处理;
75、门控注意力能够初步提取像素级特征信息,它由特征提取分支和门控分支组成,特征提取分支包括卷积核大小为1×1和3×3的卷积,门控分支包括1×1卷积和sigmoid激活函数;
76、通道注意力能够有效提取跨通道的全局信息,通过对不同通道的特征赋予不同的重要性,使得模型能够更加关注于对当前去雨任务更有用的特征;它首先采用全局平均池化操作,以提取每个通道的全局空间信息接着采用逐点卷积以学习通道间的复杂依赖关系,并用gelu激活函数来增加非线性;通过sigmoid激活函数为每个通道生成一个注意力分数,以确保注意力分数在0到1之间;最后将每个通道的注意力分数与原始特征图对应通道相乘,从而得到加权后的特征图。这加强了重要的特征通道,并抑制了不重要的通道;
77、像素注意力能够提取全局像素门控特征,它更专注于特征图中每个像素的重要性,使得模型能够在更细的层面上对特征进行加权,从而更准确地关注于对当前去雨任务更重要的局部特征;它首先采用逐点卷积和gelu激活函数来从输入特征图中学习并生成相应的像素级注意力图;接着同样用sigmoid激活函数确保注意力分数在0到1之间,并最终对原始特征图进行特征加权操作;
78、沿着通道维度将三种不同的注意力结果连接起来,并用逐点卷积-gelu-逐点卷积将连接后的特征通道维数降至与输入相同的维数,同时采用跳跃连接的方式求和得到输出的特征图;
79、最优选择稀疏注意力模块;对于一个经过层标准化的特征图首先用卷积核大小为1×1的逐点卷积聚合像素级的跨通道特征,并用卷积核大小为3×3的深度卷积来编码通道级的空间信息,从而得到根据特征图x映射的查询(q)、键(k)和值(v);
80、
81、其中表示深度卷积,表示逐点卷积;
82、原始的自注意力机制会计算每个标记(token)和其他tokens之间的相似度,进而得到注意力图;
83、引入最优选择机制来进行特征选取,在得到查询(q)、键(k)和值(v)之后,通过将q和k进行点积操作来计算所有查询和键之间的相似度,得到注意力图只保留其最大的k个自注意力分数值,而将其他的自注意力分数值设为负无穷;最后用softmax函数进行注意力分数的归一化,得到注意力权重;
84、进行将注意力权重与值(v)相乘来计算自注意力的加权和,得到每个位置的自注意力输出,用如下公式来表示:
85、
86、混合尺度前馈网络;
87、对于一个输入的特征图经过层标准化后采用1×1卷积来扩展通道数,然后将其分别送入两条并行的多尺度深度卷积路径上,并分别采用3×3和5×5深度卷积来增强多尺度局部信息提取,表示为:
88、
89、其中,f1×1表示1×1卷积,f3×3和f5×5分别表示3×3和5×5深度卷积,concat(·)表示跨通道连接;
90、注意力增强融合网络;
91、对于来自于rgb图像和红外图像的特征frgb和fir,首先通过自适应均值池化操作,将全局空间信息集成到相应的信道描述符中;为了彻底捕获不同通道之间的依赖关系,利用线性层进行映射,然后使用gelu激活这个过程产生了rgb图像特征权重wrgb和红外图像特征权重wir,表示为:
92、
93、其中,fgap表示全局均值池化,fmlp表示多层感知机;
94、采用一个相关注意力矩阵a来衡量来自于rgb图像和红外图像的特征fvis和fir之间的关系;
95、
96、其中,μ(·)表示sigmoid激活函数;系数c表示通道数,对注意力增强起比例因子的作用;表示按元素相乘;
97、在共享特征增强分支里,首先将相关注意力矩阵a与rgb特征frgb和红外特征fir进行按通道相乘,得到初始融合特征;
98、将融合后的特征通过跨通道融合增强模块进行处理:
99、
100、其中,⊙表示按通道乘积,concat(·)表示跨通道连接,f7×7表示卷积核大小为7×7的深度卷积;
101、简单地进行互补特征注意力增强,记为:
102、
103、使用空间注意力机制聚合增强的rgb和红外特征作为输出,通过以下方式得到融合后的特征:
104、
105、其中,f1×1表示卷积核大小为1×1卷积;
106、将得到的拆分得到经过融合处理的rgb图像特征和红外图像特征将它们相加得到融合特征ffuse;
107、
108、其中,split(·)表示按通道拆分;
109、注意力引导专家网络;
110、注意力引导专家网络一共包含8个专家网络,分别是:感受野为3×3的平均池化层、卷积核大小为1×1、3×3、5×5、7×7的可分离卷积层以及卷积核为3×3、5×5、7×7的膨胀卷积层;
111、对于输入的特征图首先用自适应池化层得到每个通道对应的描述符
112、
113、其中,x(i,j,k)表示特征图x的第k个通道的位于(i,j)的像素值;
114、然后利用可学习的权重矩阵w1和w2来获得每个专家网络的系数t:
115、t=w2σ(w1z),
116、
117、其中,σ(·)表示relu激活函数,f1×1表示1×1卷积,表示专家网络操作,[·]表示跨通道连接;
118、训练irdenet网络采用的是charbonnier loss损失函数,该损失函数公式如下:
119、
120、其中,igt表示真实无雨图,iderain表示irdenet生成的无雨图。
121、进一步的,步骤203具体包括:分别对真实无雨图像igt和去雨后的无雨图像iderain使用预训练的sam模型进行图像分割,得到他们对应的掩码图,接着构造损失函数来衡量两者之间的差距;构造的损失函数(seg loss)由focal loss和dice loss两部分组成:
122、
123、其中,a和β是可调节的超参数;
124、用focal loss来解决样本类别不均衡的问题,其定义为:
125、
126、其中,pt表示为:
127、
128、dice loss用来评估两个样本的相似性,它通过比较预测结果和真实标签之间的相似性来衡量分割模型的性能,其定义为:
129、
130、其中,yi表示模型预测的值,范围在0~1之间,ti表示目标值;
131、irdenet网络整体的损失函数表示为:
132、
133、本发明的有益效果是:
134、1、本发明解决了基于三维建模的游戏在进行场景转换过程中,其中人物图像及环境图像经常会出现亮度不够的情况,尤其是带有雨水的三维模型场景,严重影响用户游戏体验感的问题;
135、2、本发明有效减少图像中的高频信息,从而平滑图像并显著降低视觉噪点,此外,为了更好地保留场景图像中的边缘信息,本发明还采用了边缘保持滤波器,如双边滤波和非局部均值滤波,进行图像的清晰化处理,确保了整个图像处理流程的高效和精确;
136、3、本发明通过优化图像的对比度与细节表现,更真实地反映了场景图像中三维模型的自然色彩,使三维模型的纹理和结构变得更加明显和清晰,显著提高了图像的整体视觉质量;
137、4、本发明还能有效的去除带雨场景图片中的雨纹,确保场景转换后场景的光亮及清晰度,给用户带来真实和良好的体验感。
- 还没有人留言评论。精彩留言会获得点赞!