一种基于随机加权准则的最大互相关熵卡尔曼滤波方法
1.本发明属于信号处理技术领域,具体涉及的是一种基于随机加权准则的最大互相关熵卡尔曼滤波方法。
背景技术:
2.状态估计是信号处理中的一个重要问题。卡尔曼滤波方法是解决线性系统高斯噪声下的状态估计问题的重要方法之一,其充分利用了系统的状态模型和观测数据,通过求解的优化问题,使得状态估计的误差最小,从而来获得系统的最优估计。但是由于系统模型或者量测等原因使得噪声受到污染,常常会出现重尾非高斯噪声的情况,这会导致卡尔曼滤波算法精度下降甚至发散,因此需要针对为非高斯噪声的滤波算法。
3.针对量测噪声为非高斯的情况,目前已经出现的滤波算法有:高斯和滤波、基于huber技术的m估计滤波和基于student’s方法的t滤波。但是使用高斯和滤波要求噪声的概率密度分布已知,这在工程实用中很难实现:huber技术由于其影响函数在影响参数γ超过1.345之后不会回降,会导致估计性能下降;而学生t滤波只能用于系统噪声协方差和量测噪声协方差较小的情况。因此,提出了一种新的适用于线性系统的鲁棒性和抗噪能力都提升的卡尔曼滤波方法显得尤为重要。为此,研究人员提出一种新的解决重尾非高斯噪声的方法,即基于最大互相关熵的滤波方法,例如最大互相关熵卡尔曼滤波等。不同于传统的滤波方法,互相关熵不仅包括二阶统计信息,还包括更高阶的统计信息,因此能获得更好的估计效果。
技术实现要素:
4.本发明针对现有技术的缺陷,提供了一种基于随机加权准则的最大互相关熵卡尔曼滤波方法,适用于噪声为非高斯情况下的线性系统,提高了系统的鲁棒性和抗噪能力。
5.为了实现上述目的,本发明通过以下技术方案予以实现。
6.一种基于随机加权准则的最大互相关熵卡尔曼滤波方法,包括以下步骤:
7.步骤一:构建线性系统方程和量测方程如下:
[0008][0009]
其中k-1表示第k-1时刻,xk∈rn为第k时刻的n维系统状态向量,zk∈rm为第k时刻的m维量测向量;f
k-1
和hk分别为已知的转移矩阵和量测矩阵,q
k-1
∈rn为第k-1时刻的n维系统噪声,rk∈rm为第k时刻的m维量测噪声;系统噪声服从高斯分布q
k-1
~n(0,q
k-1
),量测噪声为非高斯服从混合高斯分布rk~λn(0,r
k,1
)+(1-λ)n(0,r
k,2
),q
k-1
和rk为不相关的过程和量测高斯噪声,满足
[0010][0011]
其中e[
·
]代表数学期望,δ
kj
是克罗内克符号函数,代表混合噪声向量rj的转置向量;
[0012]
步骤二:初始化,选择一个核宽σ,且初始化系统状态和协方差p(0|0),令k=1;
[0013]
步骤三:根据系统的一步预测方程,更新先验状态和协方差p
k|k-1
;
[0014][0015][0016]
步骤四:在固定点迭代时刻再次初始化状态值:令t=1和
[0017]
步骤五:根据初始系统和量测方程进行系统模型变形,计算新模型的误差,由此计算出误差的核函数;
[0018]
首先,将状态方程与量测方程重建:
[0019][0020][0021][0022]
其中:e[
·
]代表数学期望,p
k|k-1
是第k时刻的状态一步预测误差协方差矩阵,rk是第k时刻的量测噪声协方差矩阵,b
p
(k|k-1)是对p
k|k-1
进行cholesky分解后得到的矩阵,是b
p
(k|k-1)的转置矩阵,同理br(k)是rk进行cholesky分解后得到的矩阵,是br(k)的转置矩阵,bk是由b
p
(k|k-1)与br(k)构成的新的对角矩阵;
[0023]
在方程的两侧同时左乘以得:
[0024]dk
=wkxk+ek[0025]
其中误差向量ek第i列元素为:
[0026]ek
(i)=di(k)-wi(k)x
k(i)[0027]
其中:di(k)是dk的第i个元素,wi(k)是矩阵wk的第i行元素,xk(i)在此处代表xk的第i个状态量,且dk为l=n+m维向量;
[0028]
步骤六:由随机加权准则和核函数得出两个对角阵;
[0029]
由于随机加权准则,定义新的代价函数:
[0030][0031]
其中g
σ
(
·
)高斯核函数:
[0032]
在此取:
[0033]
则xk(i)的最优解:
[0034][0035]
矩阵化形式为:
[0036][0037]
其中且且得到两个对角矩阵
[0038]
步骤七:两个对角阵来修正一步预测协方差和量测误差协方差和量测误差协方差
[0039][0040]
从而修正增益矩阵;
[0041][0042]
步骤八:估计出系统滤波的后验状态
[0043][0044]
和协方差
[0045][0046]
若k+1=n,其中n为预设的算法迭代次数,则停止计算;否则继续执行上述步骤。
[0047]
与现有技术相比,本发明的有益效果为:
[0048]
本发明通过将随机加权准则引入mckf,提高了mckf的精确度;本发明在代价函数中采用了随机加权理论,增大了相关熵,符合最大相关熵准则(mcc),提高了估计的精度;通过实验证明,相比较于传统的kf算法和mckf算法,提高了状态估计的精度和估计的有效性。
附图说明
[0049]
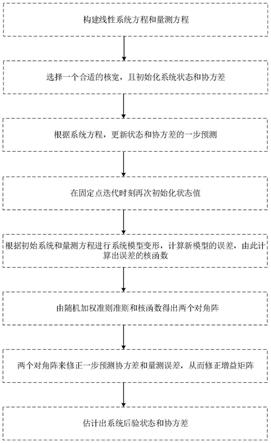
图1是本发明所述的一种基于rwmckf方法的流程图;
[0050]
图2是状态x1在kf、mckf(σ=2)和rwckf下的概率密度函数;
[0051]
图3是状态x2在kf、mckf(σ=2)和rwckf下的概率密度函数;
[0052]
图4是状态x1在mckf(σ=2)和rwckf下的概率密度函数;
[0053]
图5是状态x2在mckf(σ=2)和rwckf下的概率密度函数。
具体实施方式
[0054]
下面结合附图和实施例对本发明作进一步的详细描述。为了更好的理解本发明的方法,先对本发明网络结构做详细介绍。
[0055]
本发明为一种基于随机加权准则的最大互相关熵卡尔曼滤波的方法,包括以下几个步骤:
[0056]
步骤一:构建线性系统方程和量测方程如下:
[0057][0058]
其中k-1表示第k-1时刻,xk∈rn为第k时刻的n维系统状态向量,zk∈rm为第k时刻的m维量测向量;f
k-1
和hk分别为已知的转移矩阵和量测矩阵,q
k-1
∈rn为第k-1时刻的n维系统噪声,rk∈rm为第k时刻的m维量测噪声,假设系统噪声服从高斯分布q
k-1
~n(0,q
k-1
),量测噪声为非高斯服从混合高斯分布rk~λn(0,r
k,1
)+(1-λ)n(0,r
k,2
),q
k-1
和rk为不相关的过程和量测高斯噪声,满足
[0059][0060]
其中e[
·
]代表数学期望,δ
kj
是克罗内克符号函数,代表混合噪声向量rj的转置向量;
[0061]
步骤二:初始化,通过经验选择一个合适的核宽σ,且初始化系统状态和协方差p(0|0),令k=1;
[0062]
步骤三:根据系统的一步预测方程,更新先验状态和协方差p
k|k-1
;
[0063][0064][0065]
步骤四:在固定点迭代时刻再次初始化状态值:令t=1和
[0066]
步骤五:根据初始系统和量测方程进行系统模型变形,计算新模型的误差,由此计算出误差的核函数;
[0067]
首先,将状态方程与量测方程重建:
[0068][0069]
[0070][0071]
其中:e[
·
]代表数学期望,p
k|k-1
是第k时刻的状态一步预测误差协方差矩阵,rk是第k时刻的量测噪声协方差矩阵,b
p
(k|k-1)是对p
k|k-1
进行cholesky分解后得到的矩阵,是b
p
(k|k-1)的转置矩阵。同理br(k)是rk进行cholesky分解后得到的矩阵,是br(k)的转置矩阵,bk是由b
p
(k|k-1)与br(k)构成的新的对角矩阵;
[0072]
在方程的两侧同时左乘以得:
[0073]dk
=wkxk+ek[0074]
其中误差向量ek第i列元素为:
[0075]ek
(i)=di(k)-wi(k)x
k(i)[0076]
其中di(k)是dk的第i个元素,wi(k)是矩阵wk的第i行元素,xk(i)在此处代表xk的第i个状态量,且dk为l=n+m维向量。
[0077]
步骤六:由随机加权准则和核函数得出两个对角阵;
[0078]
由于随机加权准则,定义新的代价函数:
[0079][0080]
其中g
σ
(
·
)高斯核函数:
[0081]
在此取:
[0082]
则xk(i)的最优解:
[0083][0084]
矩阵化形式为:
[0085][0086]
其中且且得到两个对角矩阵
[0087]
步骤七:两个对角阵来修正一步预测协方差和量测误差协方差
[0088]
[0089][0090]
从而修正增益矩阵;
[0091][0092]
步骤八:估计出系统滤波的后验状态和协方差,具体为,
[0093][0094][0095]
此时就可以完成对目标状态参数的估计和状态估计误差协方差矩阵将用于下一时刻状态参数的估计。
[0096]
本发明采用的随机加权最大互相关熵卡尔曼滤波(rwmckf)算法,对于非高斯重尾噪声情况下的线性系统进行状态估计,随机加权准则的应用增强了系统的鲁棒性和提升了滤波的精度。本发明利用matlab仿真软件进行仿真实验,将rwmckf算法与现有的滤波算法kf和mckf进行比较得出,状态估计的精度和估计的有效性有很大的提升。
[0097]
下面通过具体的实施例来论证本发明。
[0098]
实施例一
[0099]
考虑一般的线性系统模型:
[0100][0101][0102]
其中θ=π/18,且系统噪声为高斯噪声qi(k-1)~n(0,2)(i=1,2),量测噪声为非高斯的混合高斯噪声r(k)~0.9n(0,1)+0.1n(0,100)。
[0103]
根据上述基于随机加权准则的最大相关熵卡尔曼滤波方法,状态初始值取误差协方差矩阵取p(0|0)=diag(100,100)。高斯核函数的核宽σ分别设置为0.1、0.5、1、2、3、5、8、10,分别与kf算法和mckf(σ=2)进行比较,得到图2、3的两个状态x1、x2在不同滤波算法下的概率密度函数。本发明提供的基于随机加权准则的最大相关熵卡尔曼滤波方法的仿真结果见曲线rwmckf,可见较传统kf和mckf,性能优势明显:kf算法在重尾量测噪声情况下是有偏的,mckf和rwmckf是无偏的,但rwckf算法的无偏性相对于mckf算法更具有优势。
[0104]
关于高斯核函数的核宽σ对本发明的提供的随机加权准则的最大相关熵卡尔曼滤波的影响可以通过图3、4得出:rwckf与mckf有相似点是σ=2的有效性最好。
[0105]
实施例二:
[0106]
更换仿真模型为一维线性匀加速运动,系统模型和量测模型如下:
[0107]
[0108][0109]
其中δt=0.1s,且系统噪声和量测噪声均为非线性混合高斯噪声:
[0110]
q1(k-1)~0.9n(0,0.01)+0.1n(0,1)
[0111]
q2(k-1)~0.9n(0,0.01)+0.1n(0,1)
[0112]
q3(k-1)~0.9n(0,0.01)+0.1n(0,1)
[0113]
r(k)~0.8n(0,0.01)+0.2n(0,100)。
[0114]
根据上述基于随机加权准则的最大相关熵卡尔曼滤波方法,首先初始化滤波算法。状态初值和协方差初值分别设置为x(0)=[001]
t
,p(0|0)=diag(0.01,0.01,0.01)。高斯核函数的核宽σ设置为2(即为实施例1中相对来说最优核宽),则可以得到kf,mckf(σ=2)和rwmckf(σ=2)算法下的均方误差表:
[0115]
表
ⅰꢀ
kf,mckf(σ=2)和rwmckf(σ=2)算法下的均方误差
[0116][0117]
表ⅰ分别给出了kf、mckf(σ=2)和rwmckf(σ=2)三种算法下的均方误差,从表ⅰ可得出:在相同的混合高斯系统和量测噪声影响下,基于随机加权准则的最大相关熵卡尔曼滤波方差的均方误差最小,说明该算法的性能较kf和mckf有较大的提升。
[0118]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1