话单采集系统在双活场景下的业务分流方法、装置及系统与流程
本发明涉及网络,尤其涉及一种话单采集系统在双活场景下的业务分流方法、装置及系统。
背景技术:
1、话单容灾是指在不同的两地分别建立数据中心,当一数据中心出现问题时,将业务切换到另一数据中心。但如果其中一数据中心一直冷备,则可能导致灾难发生时不敢去切到冷备的数据中心。最重要的是如果发生灾难进行了切换,那么需要考虑灾难机房的恢复能力,如何切换回去,数据如何恢复,还有同步数据所产生的跨机房流量问题,而现有技术的解决方式就是简单地按照用户粒度进行分流,而话单采集系统业务具有其特殊性,无法简单地按照用户粒度进行分流,因为话单采集系统数据量大、处理逻辑复杂、话单关联性和业务需求的多样性等因素,具体如下:
2、1.话单采集系统的数据量大:话单采集系统通常处理的是大量的话单数据,这些数据的规模往往很大,涉及到海量的用户和交易信息。如果按照简单的用户粒度进行分流,会导致某些用户的数据量过大,造成负载不均衡和性能瓶颈。
3、2.话单的处理逻辑复杂:话单采集系统需要对话单进行复杂的处理和分析,包括数据清洗、格式转换、验证、计算等操作。这些操作涉及到多个步骤和多个模块的协同工作,无法简单地按照用户粒度进行分流。
4、3.话单之间的关联性:在话单采集系统中,不同用户的话单之间可能存在关联性,需要进行跨用户的数据分析和处理。如果按照简单的用户粒度进行分流,可能会导致关联的话单被分到不同的处理节点上,影响数据的一致性和准确性。
5、4.业务需求的多样性:不同用户的业务需求可能各不相同,需要进行个性化的处理和分析。如果按照简单的用户粒度进行分流,无法满足不同用户的个性化需求,导致业务处理的效果不佳。
技术实现思路
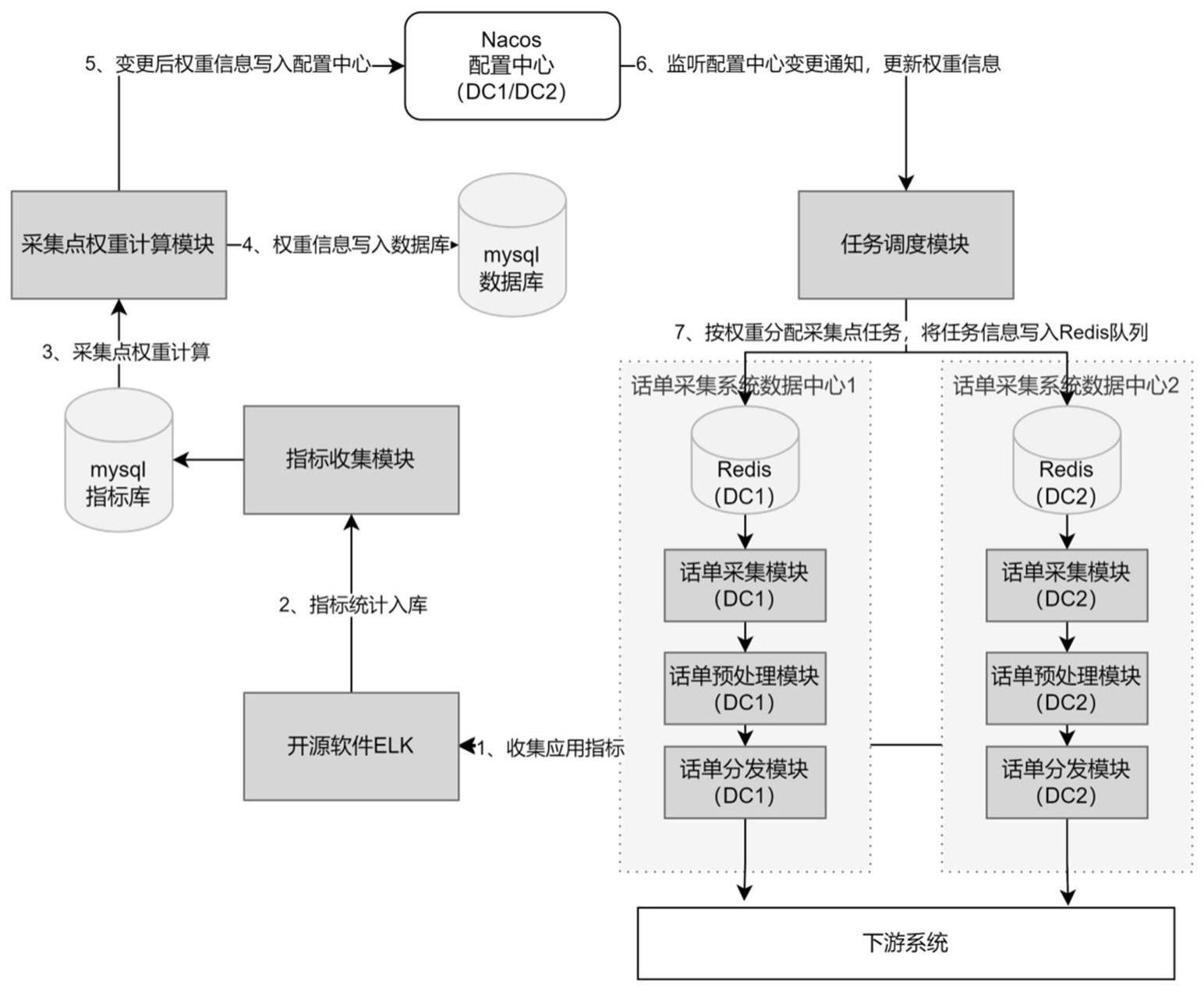
1、本发明所要解决的技术问题是针对现有技术的上述不足,提出一种话单采集系统在双活场景下的业务分流方法、装置及系统。该方法通过采集点权重计算以及采集点归属数据中心计算,最大程度的保障了业务分配的准确性,从而能够充分利用两个数据中心的资源。
2、第一方面,本发明提供一种话单采集系统在双活场景下的业务分流方法,所述方法包括如下步骤:
3、步骤s1:获取目标es指标数据;
4、步骤s2:根据目标es指标数据获得采集权重信息,所述采集权重信息包括各个采集点的权重值;
5、步骤s3:将采集权重信息分别写入第一配置中心和第二配置中心,所述第一配置中心为dc1中部署的nacos配置中心,所述第二配置中心为dc2中部署的nacos配置中心;
6、步骤s4:监听第一配置中心和第二配置中心,并判断第一配置中心和第二配置中心是否正常:
7、若第一配置中心正常、且第二配置中心正常,则进入步骤s5;若第一配置中心正常、且第二配置中心异常,则将所有采集点业务均分配给dc1;若第一配置中心异常、且第二配置中心正常,则将所有采集点业务均分配给dc2;若第一配置中心异常、且第二配置中心异常,则执行错误处理并结束流程;
8、步骤s5:根据分配给dc1和dc2的业务量比例,计算出采集点归属数据中心;
9、步骤s6:根据采集点归属数据中心,对dc1承载的采集点任务、和dc2承载的采集点任务分别进行调度,以实现话单采集系统在双活场景下的业务分流;
10、其中,dc1和dc2为两个互为主备的数据中心,dc1上部署有第一mysql数据库,dc2上部署有第二mysql数据库,第一mysql数据库和第二mysql数据库之间通过binlog实现数据双向同步。
11、进一步地,所述步骤s1中,是通过开源软件elk进行日志收集,获得目标es指标数据的。
12、进一步地,所述步骤s2中,根据目标es指标数据得到采集权重信息,具体包括步骤:
13、步骤s21:通过elasticsearch连接es集群,获取到所需的目标es指标数据,所述目标指标数据包括各个采集点的文件数、文件大小及话单条数;
14、步骤s22:对获取到的目标es指标数据按权重进行归一处理,获得采集权重信息。
15、进一步地,所述步骤s22,包括如下步骤:
16、步骤s221:计算每个指标的归一化权重,所述每个指标的归一化权重是每个指标的权重在所有指标权重的占比,计算公式如下:
17、归一化权重=(原始权重/总权重)*100%
18、步骤s222:对于每个指标,使用归一化函数对指标值进行归一化计算:
19、归一化指标值=归一化权重*(指标值-min)/(max-min);
20、max为指标最大值,min为指标最小值。
21、进一步地,所述步骤s5,根据分配给dc1和dc2的业务量比例,计算出采集点归属数据中心,具体包括:
22、步骤s51:获取分配给两个数据中心dc1和dc2中的业务量分流比,将两个业务量分流进行比较,得出分流比较大的数据中心为x,分流比较小的数据中心为y;
23、步骤s52:将采集点权重所占百分比数据从大到小排序;
24、步骤s53:创建一个空的列表list1用于存放归属于分流比x的采集点,创建一个空的列表list2用于存放归属于分流比y的采集点;
25、步骤s54:遍历排序后的采集点权重数据列表:
26、对于每个采集点权重值,将其加到记录累加值z上,并将当前采集点写入列表list1;判断记录累加值z是否大于或等于分流比x,若满足条件,则跳出循环,结束遍历;其中记录累加值z的初始值为0;
27、步骤s55:遍历结束后,将剩余未遍历到的采集点写入列表list2;
28、步骤s56:采集点列表list1归属于分流比x对应的数据中心,采集点列表list2归属于分流比y对应的数据中心,以得到采集点归属数据中心。
29、进一步地,所述步骤s6中,dc1承载的采集点任务包括:话单采集、话单预处理及话单分发;
30、所述步骤s6中,dc2承载的采集点任务包括:话单采集、话单预处理及话单分发。
31、第二方面,本发明提供一种话单采集系统在双活场景下的业务分流装置,所述装置包括:
32、第一获取单元,用于获取目标es指标数据;
33、第二获取单元,与所述第一获取单元连接,用于根据目标es指标数据得到采集权重信息,所述采集权重信息包括各个采集点的权重值;
34、写入单元,与所述第二获取单元连接,用于将采集权重信息分别写入第一配置中心和第二配置中心,所述第一配置中心为dc1中部署的nacos配置中心,所述第二配置中心为dc2中部署的nacos配置中心;
35、监听单元,与所述写入单元连接,用于监听第一配置中心和第二配置中心,并判断第一配置中心和第二配置中心是否正常,并在判定第一配置中心和第二配置中心均正常时,发送正常信号;
36、计算单元,与所述监听单元连接,用于在接收到所述正常信号后,根据分配给dc1和dc2的业务量比例,计算出采集点归属数据中心;
37、调度单元,与所述计算单元连接,用于根据采集点归属数据中心,对dc1承载的采集点任务、和dc2承载的采集点任务分别进行调度,以实现话单采集系统在双活场景下的业务分流;
38、其中,dc1和dc2为两个互为主备的数据中心,dc1上部署有第一mysql数据库,dc2上部署有第二mysql数据库,第一mysql数据库和第二mysql数据库之间通过binlog实现数据双向同步。
39、进一步地,所述第二获取单元包括:
40、获取模块,用于通过elasticsearch连接es集群,获取到所需的目标es指标数据,所述目标指标数据包括各个采集点的文件数、文件大小及话单条数;
41、归一模块,与所述获取模块连接,用于对获取到的目标es指标数据按权重进行归一处理,获得采集权重信息。
42、进一步地,所述计算单元包括:
43、接收模块,用于接收监听单元发送的正常信号;
44、比较模块,与所述接收模块连接,用于收到所述正常信号后,取得分配给两个数据中心dc1和dc2中的业务量分流比,并将两个业务量分流比进行比较,得出分流比较大的数据中心为x,分流比较小的数据中心为y;
45、排序模块,与所述比较模块连接,用于将采集点权重所占百分比数据从大到小排序;
46、创建模块,与所述排序模块连接,用于创建一个空的列表list1用于存放归属于分流比x的采集点,及创建一个空的列表list2用于存放归属于分流比y的采集点;
47、遍历模块,与所述创建模块连接,用于遍历排序后的采集点权重数据列表:
48、对于每个采集点权重值,将其加到记录累加值z上,并将当前采集点写入列表list1;判断记录累加值z是否大于或等于分流比x,若满足条件,则跳出循环,结束遍历;其中记录累加值z的初始值为0;
49、写入模块,与所述遍历模块连接,用于遍历结束后,将剩余未遍历到的采集点写入列表list2;
50、归属模块,与所述写入模块连接,用于采集点列表list1归属于分流比x对应的数据中心,采集点列表list2归属于分流比y对应的数据中心,以得到采集点归属数据中心。
51、第三方面,本发明提供一种话单采集系统在双活场景下的业务分流系统,所述系统包括:
52、指标收集模块,用于获取目标es指标数据;
53、采集点权重计算模块,与所述指标收集模块连接,用于根据目标es指标数据得到采集权重信息,所述采集权重信息包括各个采集点的权重值;
54、所述采集点权重计算模块还用于将采集权重信息分别写入第一配置中心和第二配置中心,所述第一配置中心为dc1中部署的nacos配置中心,所述第二配置中心为dc2中部署的nacos配置中心;
55、任务调度模块,与所述采集点权重计算模块连接,用于根据分配给dc1和dc2的业务量比例,计算出采集点归属数据中心;
56、所述任务调度模块还用于根据采集点归属数据中心,对dc1承载的采集点任务、和dc2承载的采集点任务分别进行调度,以实现话单采集系统在双活场景下的业务分流;
57、其中,dc1和dc2为两个互为主备的数据中心,dc1上部署有第一mysql数据库,dc2上部署有第二mysql数据库,第一mysql数据库和第二mysql数据库之间通过binlog实现数据双向同步。
58、本发明的有益效果:
59、1.本发明通过采集点权重计算以及采集点归属数据中心计算,最大程度的保障了业务分配的准确性,从而能够充分利用两个数据中心的资源。
60、2.本发明采用的业务分流方案在两地建立数据中心,各自独立承载业务,不需要跨机房访问数据,并且只需要调整分流比例即可应对各种类型的灾备场景,两个数据中心都处于再用状态不必考虑不敢切换的问题,大大提高了系统的可用性。
61、3.话单采集系统处理的采集点多种多样,包括语音、数据、短信、增值等业务,所以各采集点的话单量大小差异巨大,单纯采集点个数进行任务分配,会导致两个数据中心处理的话单文件量与预设的分流比例相差较大,所以引入采集点权重计算以及采集点归属数据中心计算,最大程度的保障了业务分配的准确性,结合此方案可以一键调整业务流量,更好的利用了两个数据中心的资源。
- 还没有人留言评论。精彩留言会获得点赞!